DOM的全称是Document Object Model(文档对象模型)。
DOM是一棵树(tree),树上有Node,Node分为Document(html)、Element(元素)和Text(文本),其他不重要。
看以下图示: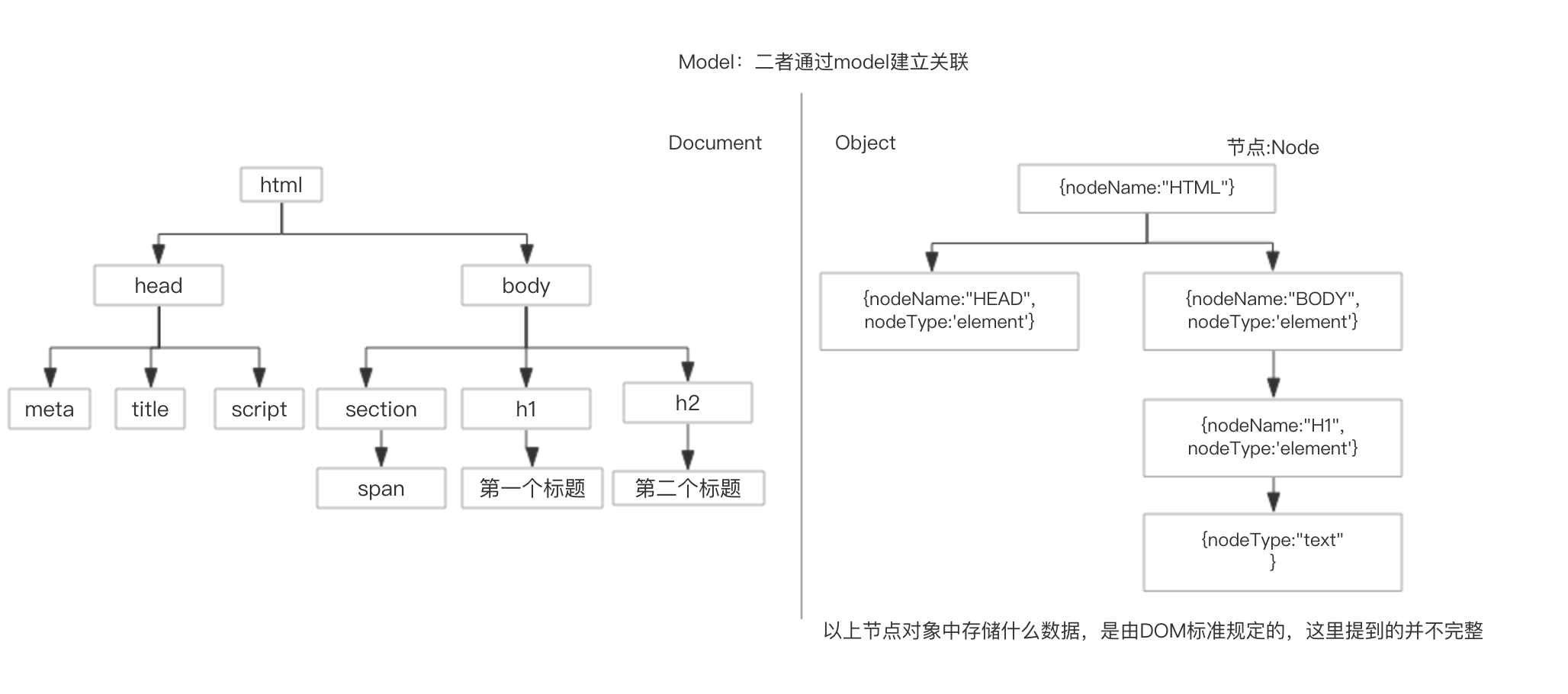
以上是文档和对象对比图,二者通过model建立关系。Node节点示意图: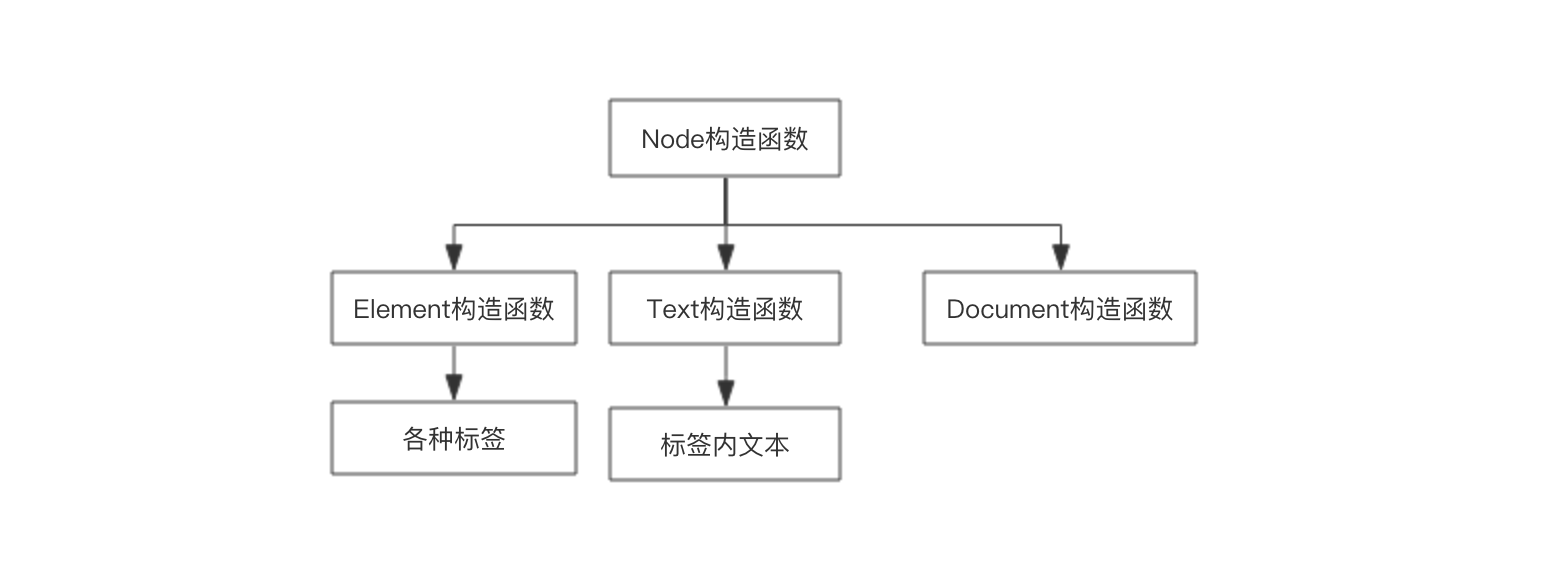
Node也是一个对象,其原型指向Object.prototype。
页面上所有标签都有对应的构造函数,如果页面中有注释,以上还会存在一个Comment构造函数,其原型指向Node构造函数。
Dom的主要功能是使页面中的节点通过构造函数生成对象。
一、Node接口
1、属性:
- childNodes //会返回包括回车/空格在内的子元素,节点类型为text,及获取子节点
- firstChild //获取第一个元素,包含空格/回车
- innerText
- lastChild
- nextSibling
- nodeName
- nodeType
- nodeValue
- outerText
- ownerDocument
- parentElement
- parentNode
- previousSibling
- textContent
这里说明以下Node节点的几种类型:
| 常量 | 值 | 描述 |
|---|---|---|
| Node.ELEMENT_NODE | 1 | 一个元素节点,如<\div>和<\p> |
| Node.TEXT | 3 | Element或者Attr中的实际文字 |
| Node.PROCESSING_INSTRUCTION_NODE | 7 | 一个用于XML文档的ProcessingInstruction,例如<?xml-stylesheet .. ?> 声明 |
| Node.COMMENT_NODE | 8 | 一个 Comment节点 |
| Node.DOCUMENT_NODE | 9 | 一个Document节点 |
| Node.DOCUMENT_TYPE_NODE | 10 | 描述文档类型的DocumentType节点,如<!DOCTYPE html>就是用于HTML5的 |
| Node.DOCUMENT_FRAGMENT_NODE | 11 | 一个DocumentFragment节点 |
2、方法
- appendChild() //添加子元素
- cloneNOde() //复制一个节点,如果使用时cloneNode(true)则会克隆其全部子元素,否则只克隆当前标签,默认为false
- contains() //判断一个元素是否包含另外一个元素
- hasChildNodes() //判断一个元素是否有子元素
- insertBefore() //将xxx插入到此节点前面
- isEqualNode() //是否是相等的节点,这个只是两个节点看起来一样
- isSameNode() //是否是相同的节点,这两个节点必须是同一个才为true
- removeChild() //移除后, 此节点不会在页面中显示,但是仍保留在内存中
- replaceNode() //替换节点
- normalize() //常规化
以上,重点掌握innerText和textContent的区别,以及nodeType的不同类型。
1) innerText是IE开发出来的API,textContent是FF开发出来的API
2) textContent会获取所有内容,包括<style>和<script>标签及其内容
3) innerText会意识到样式,不会返回隐藏文本,textContent会返回
4)因为innerText受css样式影响,他会触发重排,而textConent不会,所以textContet获取会比较快
5)与textConent不同的是,在IEIE(<IE11)中对innerText进行修改,不仅会移除当前元素的节点,还会永久的破坏所有后代文本节点
二、Document接口
1、属性
- anchors //返回当前文档中的所有锚点元素,不过目前已经被弃用。由于向后兼容,只会返回拥有name属性的a元素,而不是那些拥有id的a元素
- body //获取body元素
- characterSet //获取字符编码,如document.characterSet会返回”UTF-8”
- childElementCount //获取子元素个数,如document.childElementCount返回1,因为document下是html元素,只有一个
- children //只返回标签元素,即获取子标签,注意与childNodes区别
- doctype
- documentElement //html元素,文档对象的根元素
- domain //获取域名
- head
- hidden //文档是否被隐藏
- images //获取页面中所有image标签
- links //获取页面中所有a标签
- location //获取当前页面路径相关的所有信息包括域名、协议、路径、端口等
- onxxxxxxx //获取当前页面所有事件,如onclick、onmouseleave等等
- origin
- plugins //可用于判断是否开启flash插件
- readyState //返回页面状态,如果已经加载完,则返回”complete”
- referrer //引荐者,即是从哪个页面跳转过来的,可在请求头中查询到
- scripts
- scrollingElement //正在滚动的元素,即用户正在哪个元素上滚动
- styleSheets
- title
- visibilityState
- firstElementChild //返回第一个标签元素
2、方法
- close() //关闭文档
- createDocumentFragment()
- createElement()
- createTextNode()
- execCommand() //执行命令,即:用户在页面选中文字,在控制台输入document.execCommand(‘copy’);则会输出选中文字内容,需检查浏览器兼容性
- exitFullscreen()
- getElementById()
- getElementsByClassName()
- getElementsByName()
- getElementsByTagName()
- getSelection() //获取用户选中文本
- hasFocus()
- open()
- querySelector()
- querySelectorAll()
- registerElement()
- write() //写
- writeln() //写一行,会出现空格
三、Tips
1、请看代码:
1
2
3
4
5
6
7
8......
<div id = x></div>
<div id = parent></div>
......
<script>
console.log(x); //x是这个id为x对应的Element的对象
console.log(parent); //因为parent为全局变量,所以会直接输出Window,为避免这个问题,我们可以声明一个局部parent变量,然后进行赋值再输出就能够获取当前div。
</script>
以上问题的另外一种解决方法是定义一个函数,相当于一个局部作用域,在此作用域内声明并调用parent,例:1
2
3
4
5
6
7<script>
function x(){
var parent = document.querySelector('parent');
console.log(parent)
}
x.call();
</script>
根据以上代码可以将上述x()方法写成立即调用形式,做法是声明一个函数然后直接调用:1
2
3
4function(){
var parent = document.querySelector('parent');
console.log(parent)
}.call()
以上写法在浏览器中经常报错,解决的方法有:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24(function(){
var parent = document.querySelector('parent');
console.log(parent)
}.call())
********或者********
(function(){
var parent = document.querySelector('parent');
console.log(parent)
}).call()
********或者********
-function(){
var parent = document.querySelector('parent');
console.log(parent)
}.call()
********或者使用+/!/~这三种符号都没问题********
********或者使用let********
{
var parent = docuemnt.querySelector('#parent');
console.log(parent); //此种写法会覆盖全局变量parent,正确写法如下:
}
{
let parent = docuemnt.querySelector('#parent');
console.log(parent); //{}+let变量构成局部作用域
}